Duos
The Role of Instruction Following in Image vs. Language Models
October 15, 2023Should image generation models be as instruction-faithful as text-based models? Or is some creative leeway beneficial?

Follow up work: LeWitt Bench by Design Arena.
The Comparative Significance of Instruction Following in Language and Image Models
Instruction following has been a critical factor in the widespread adoption of language models. Projects like InstructGPT, based on extensive instruction-tuning research, have made these models incredibly useful for everyday tasks without requiring fine-tuning. Consequently, a model’s ability to follow instructions is often used as a key metric for evaluating its effectiveness.
In contrast, the development of instruction following for visual models appears to lag behind in consumer adoption. While there is some research inspired by instruction-tuning in language models—such as DALL·E 2, InstructPix2Pix, and LLaVAR (which focuses more on visual QA tasks than image generation)—a core hypothesis I explore in this post is that image models may not need to be as strictly faithful to instructions as their text-based counterparts to be useful.
Take, for example, the scenarios of “an astronaut riding a horse” versus “a horse riding an astronaut.” Even the latest DALL·E 3 model doesn’t always precisely follow these instructions in its generated images.
| DALL·E 3 interpretations of “an astronaut riding a horse”: | |

|

|
| DALL·E 3 interpretations of “a horse riding an astronaut”: | |

|

|
Evaluating Image Models’ Instruction Following Using Sol LeWitt’s Conceptual Art
With this context in mind, I’m intrigued to explore how well the latest DALL·E 3 model can follow instructions—both from an evaluative and an artistic perspective.
Years ago, I was captivated by Sol LeWitt’s instruction-based art during a visit to New York. In this conceptual art form, the instructions themselves become the art, open to interpretation and implementation by different people. This innovative approach predates generative art and has influenced my previous works, such as Prelude to a Civilization.
Last November, I compiled a small dataset featuring LeWitt’s works to test if state-of-the-art (SOTA) image generation models could accurately interpret and generate images based on these instructions.
The result? They fell short.
Fast forward to today, and it’s time to reassess how these models have evolved in their ability to follow instructions.
Results and Observations
Due to the unavailability of the DALL·E 3 API, my tests were limited to a small sample of instructions (N = 6). I used ChatGPT 4 in conjunction with DALL·E 3, Midjourney, and Stable Diffusion 2.1 for these tests. All generated results can be viewed in the lewitt_instructions/20231015_eval repository.
Here are some key qualitative observations:
-
DALL·E 3, while improved, still does not faithfully adhere to given instructions. A clear example is when the model was asked to divide a space into six parts but failed to do so accurately.
-
The prompt translation capabilities of ChatGPT are commendable and highly accurate. However, this doesn’t appear to significantly assist other models in following instructions more closely.
-
Among the models tested, DALL·E 3 shows the highest image generation quality. It also exhibits a tendency to add a third dimension, incorporating shadows and perspectives rather than sticking to a flat design.
A Case Study: Following Instructions with LeWitt Wall Drawing 340
LeWitt Wall Drawing 340 at MASS MoCA:
Six-part drawing. The wall is divided horizontally and vertically into six equal parts. 1st part: On red, blue horizontal parallel lines, and in the center, a circle within which are yellow vertical parallel lines; 2nd part: On yellow, red horizontal parallel lines, and in the center, a square within which are blue vertical parallel lines; 3rd part: On blue, yellow horizontal parallel lines, and in the center, a triangle within which are red vertical parallel lines; 4th part: On red, yellow horizontal parallel lines, and in the center, a rectangle within which are blue vertical parallel lines; 5th part: On yellow, blue horizontal parallel lines, and in the center, a trapezoid within which are red vertical parallel lines; 6th part: On blue, red horizontal parallel lines, and in the center, a parallelogram within which are yellow vertical parallel lines. The horizontal lines do not enter the figures.

DALL·E 3 Interpretations



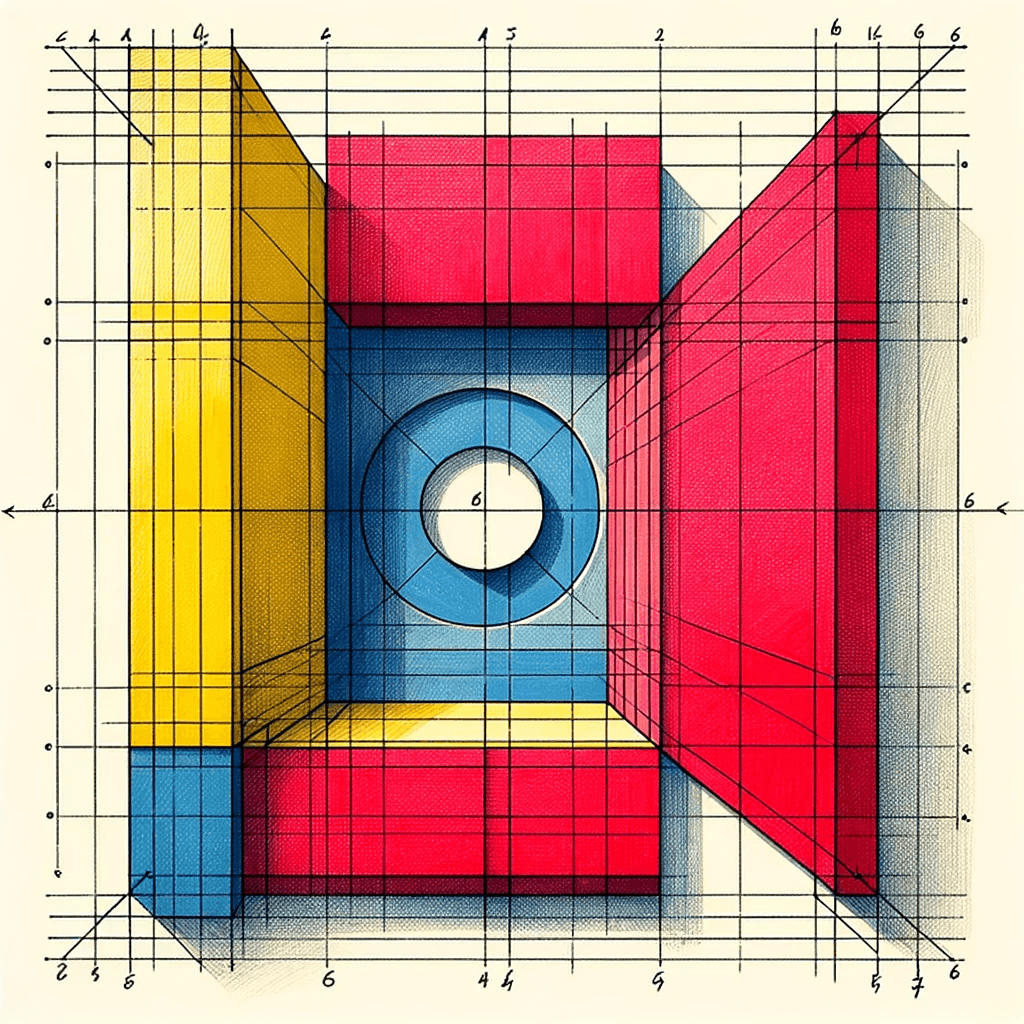
Midjourney Interpretations

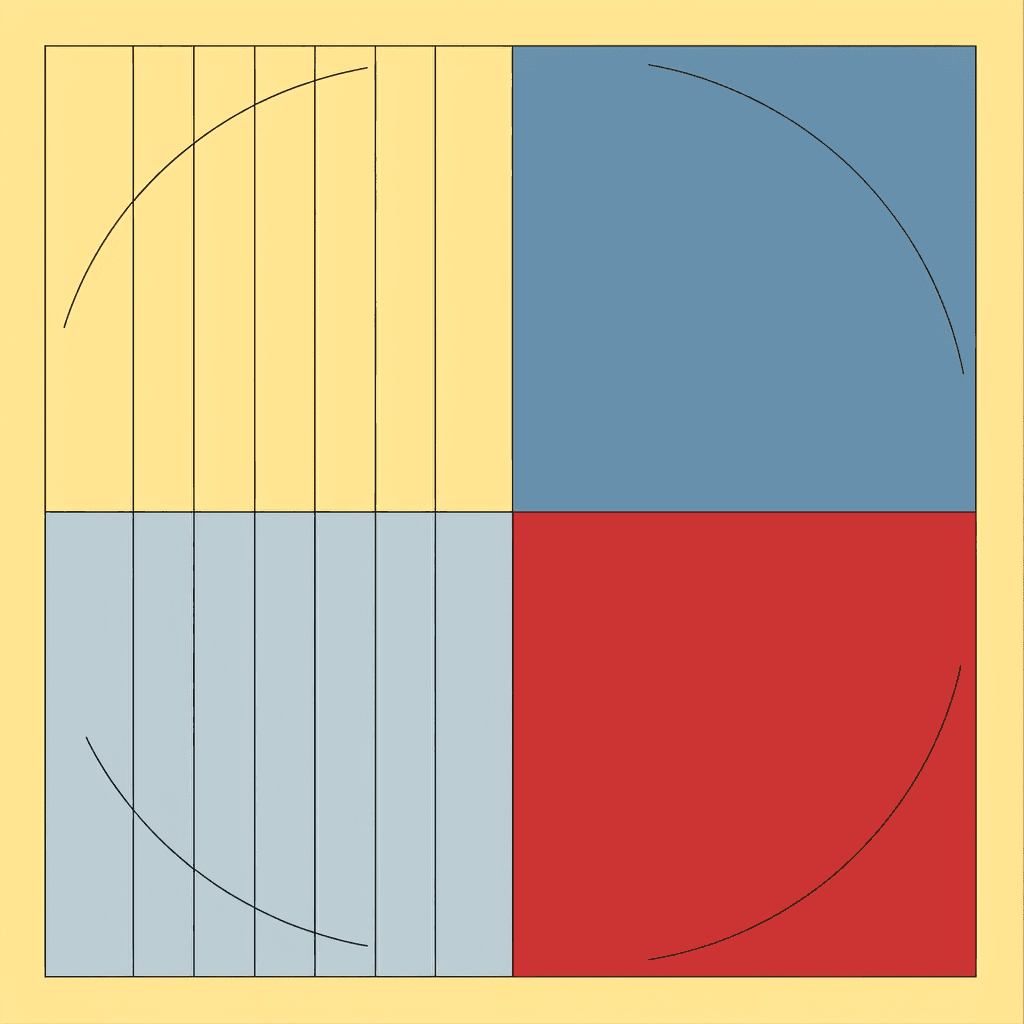


Stable Diffusion 2.1 Interpretations




This section serves as a detailed case study using Sol LeWitt’s Wall Drawing 340. The generated images from DALL·E 3, Midjourney, and Stable Diffusion 2.1 each offer a unique interpretation of the original instructions, providing valuable insights into the models’ capabilities and limitations.
Exploring the Role of ChatGPT Prompt Translation
Translated Prompt
The prompt translated by ChatGPT served as a more structured set of instructions, aiming to bridge the gap between human language and machine understanding. For example, the translated prompt for LeWitt Wall Drawing 340 was:
Drawing segmented into six parts, both vertically and horizontally. In the 1st section, a red background has blue horizontal parallel lines with a circle in the center, inside of which are yellow vertical lines. In the 2nd section, a yellow background has red horizontal lines with a square in the center that houses blue vertical lines. The 3rd section has a blue background with yellow horizontal lines and a triangle in the center with red vertical lines. The 4th section showcases a red background with yellow horizontal lines and a rectangle in the center with blue vertical lines. The 5th has a yellow background, blue horizontal lines, and a trapezoid in the center with red vertical lines. The 6th part is blue with red horizontal lines and a parallelogram in the center with yellow vertical lines. The horizontal lines are outside the shapes.
This suggests that the language model’s ability to understand and translate intricate instructions is relatively high compared to the current state of image models.
Controlled Experiment: Using Translated Prompts with Midjourney
In a controlled experiment, the prompt translated by ChatGPT was used to instruct the Midjourney model, aiming to isolate the role of instruction clarity in the generated output. Unfortunately, the results indicated that even with a more explicit set of instructions, the model’s image generation capabilities did not significantly improve.

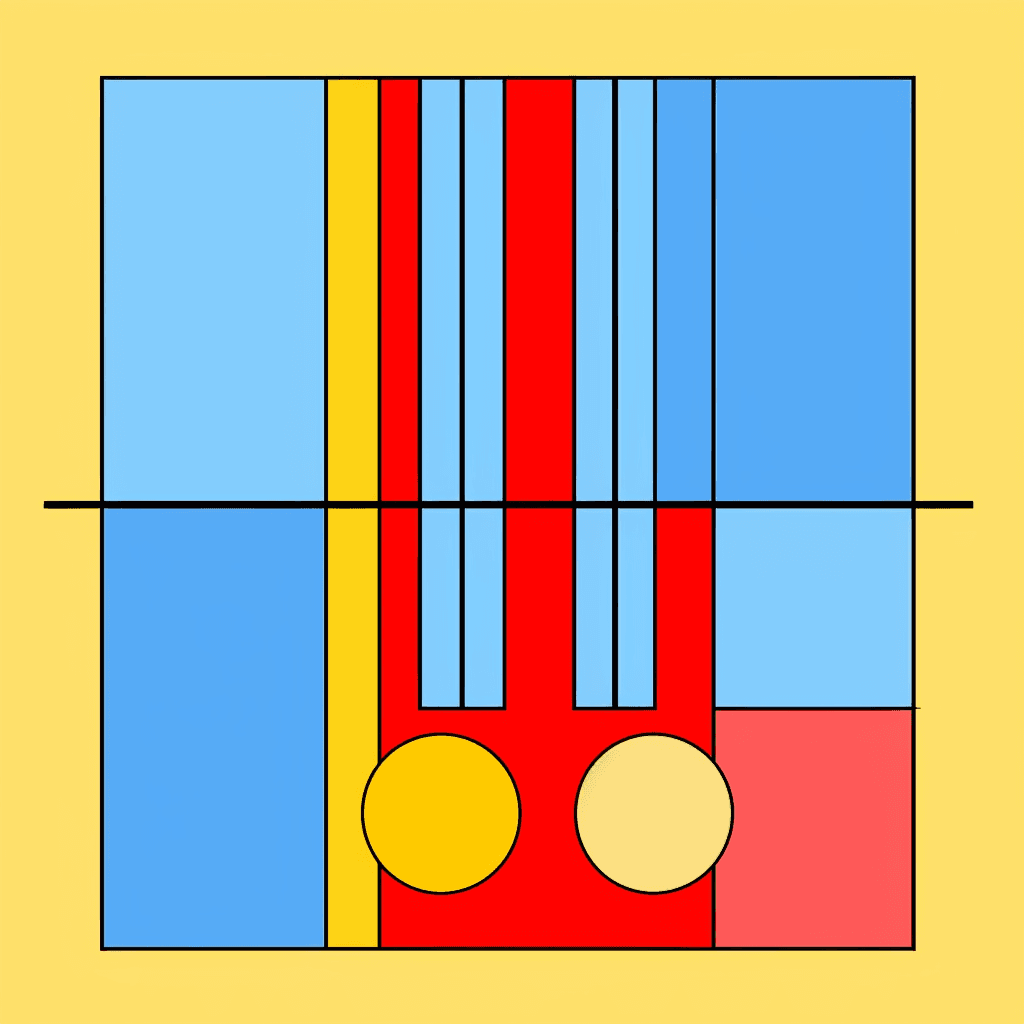


Observations
This experiment implies that the issue may not entirely lie in the language-to-language translation but in the language-to-image translation. Despite the clarity and detail in the prompt, the image models, including Midjourney, were still unable to faithfully execute the instructions. This provides more evidence to the idea that current image models have room for improvement in terms of following complex instructions.
Distinct Aesthetic Styles of Image Generators
Midjourney: A Unique Visual Identity
Midjourney is appreciated for its very distinct style. It is often hard to put in words but comes across as sleek, somewhat Studio Ghibli-esque, but also leans towards surreal and cyberpunk themes.
DALL·E 3: A Modern Illustrator’s Touch
DALL·E 3 takes on a different aesthetic direction. It often produces images that are smooth, detailed, modern, and vibrant. One common observation is its tendency to generate three-dimensional shapes, shadows, and perspectives, deviating from flat design principles.
Style Cues vs Content Instructions
Interestingly, DALL·E 3 is better at following stylistic cues than complex instructions. For instance, when prompted to generate images in the flat design style, it does so reasonably well, though there are still shortcomings in following the content instructions faithfully.
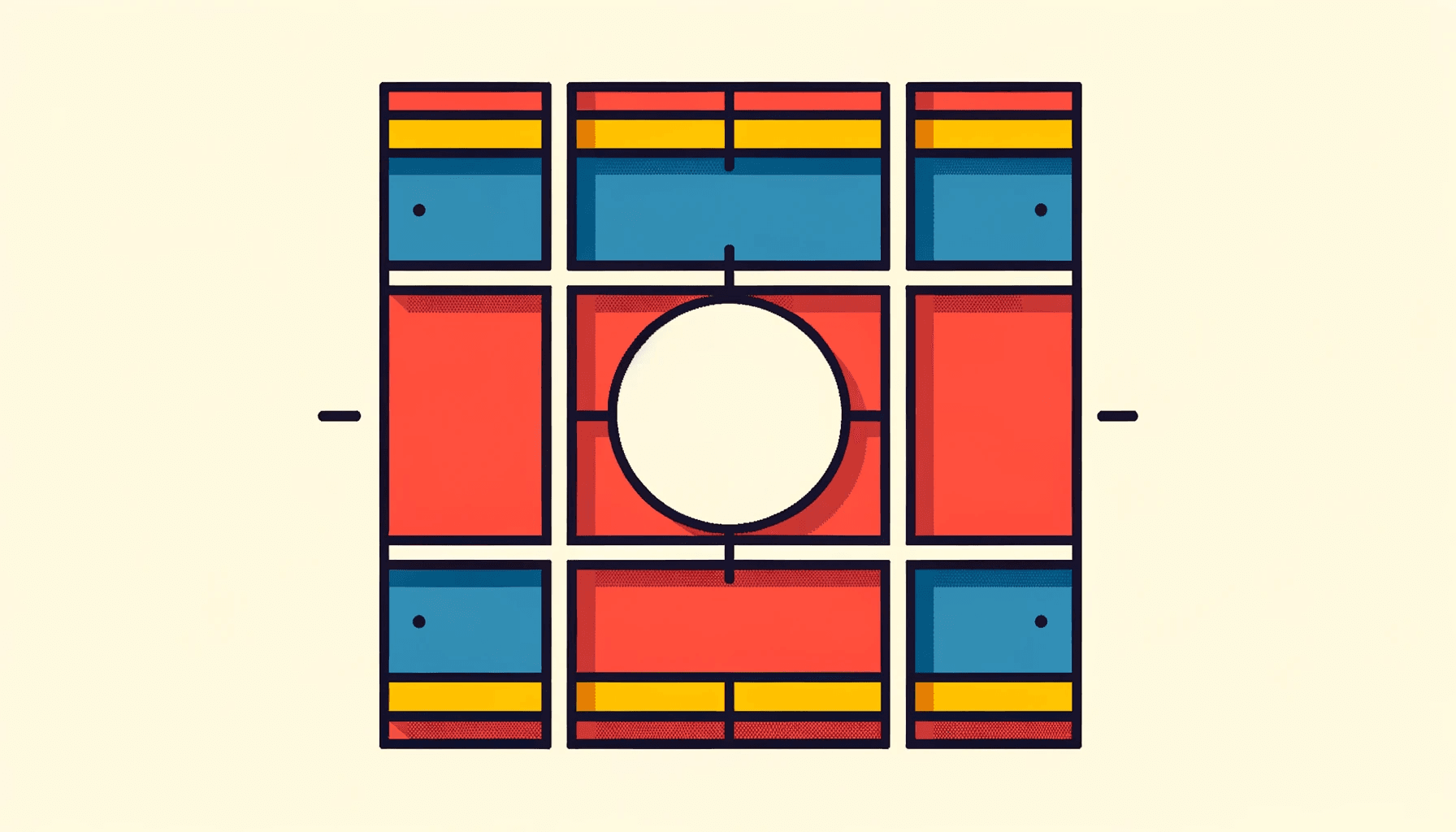



Discussion
DALL·E 3’s capacity to adapt to a stylistic prompt—such as flat design—while not adhering closely to intricate instructions is telling. This observation could be indicative of the model’s strengths and weaknesses. It is strong at translating simple, straightforward stylistic cues but faces difficulties when it comes to following complex sets of rules, especially when those rules have to work in conjunction with each other.
This might also signify the inherent challenges in training image models to accurately map complex sets of textual instructions to visual outputs.
Research Idea: Leveraging Language Models for Synthetic Data Augmentation
One compelling avenue for research involves synthetic data augmentation using LeWitt’s instructional style. Given the advancements in language models’ ability to follow instructions, it becomes increasingly viable to employ them for writing p5.js programs that adhere closely to LeWitt’s guidelines.
Multi-Step Pipeline
The research involves a multi-step pipeline:
- Textual Instruction to Code: Utilize a language model, such as GPT-4, to convert complex textual instructions into executable p5.js code.
- Code Execution: Run the generated code through an interpreter like the p5.js Web Editor to produce the actual images.
- Synthetic Data Generation: Leverage the generated images as synthetic data to train or fine-tune other machine learning models, specifically those that generate images.
Experiment Overview
For testing, I used a zero-shot prompt to instruct GPT-4 to generate p5.js code that renders an image. This code was then executed in a code interpreter, such as the p5.js Web Editor. The generated image closely followed the given instructions, outperforming images directly generated by image models, albeit potentially lacking in aesthetic quality.
The prompt used is as follows:
write p5.js code to draw this. Follow the instructions as closely as possible.
{prompt}Extending Diversity in Synthetic Data
To further diversify our synthetic data pool, we can directly use prompts generated by ChatGPT. Here is an example where a ChatGPT-generated prompt was transformed through the pipeline.
Image Comparisons
Original Sol LeWitt Wall Drawing 340 for reference:
Synthetic data generated through the text -> code -> image pipeline:
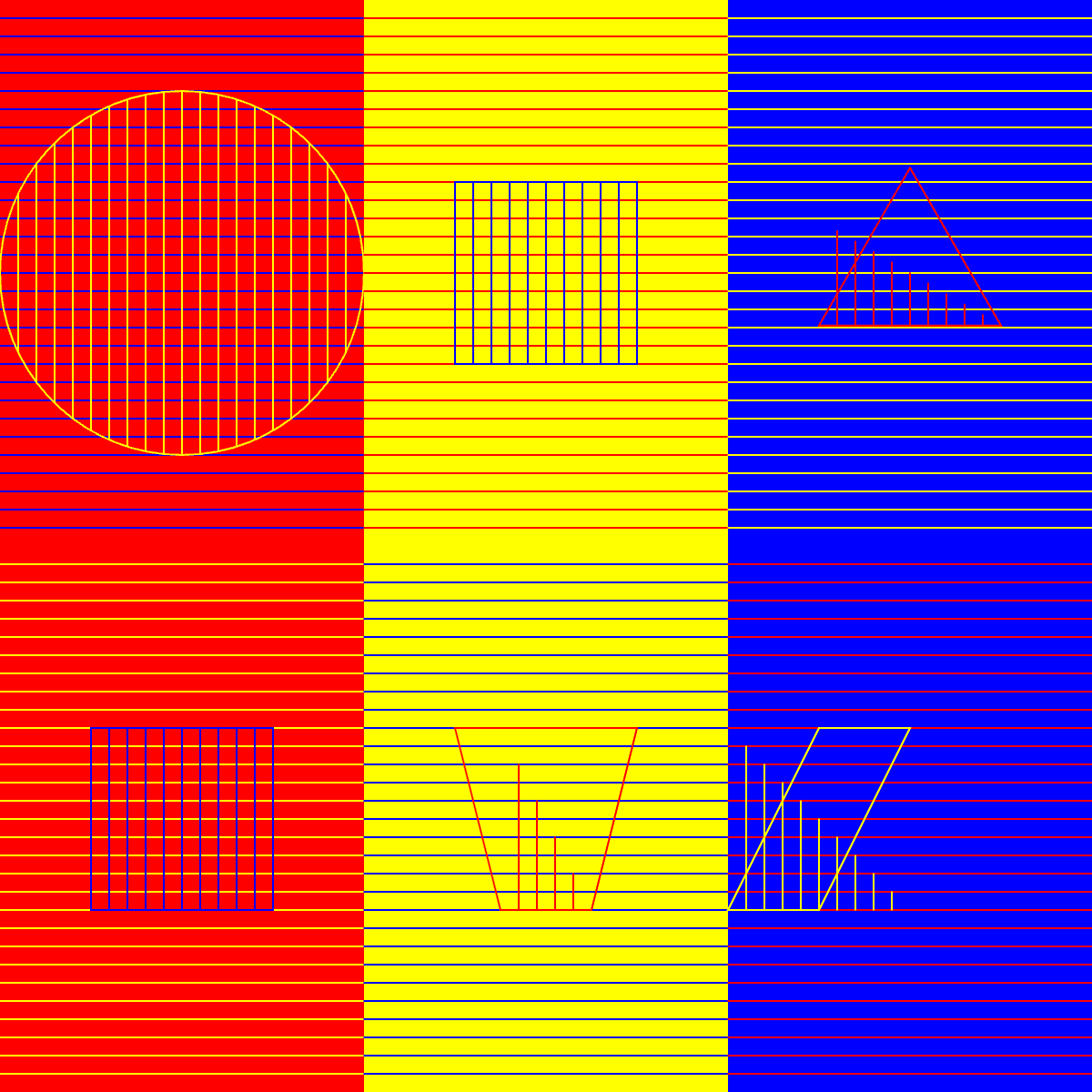
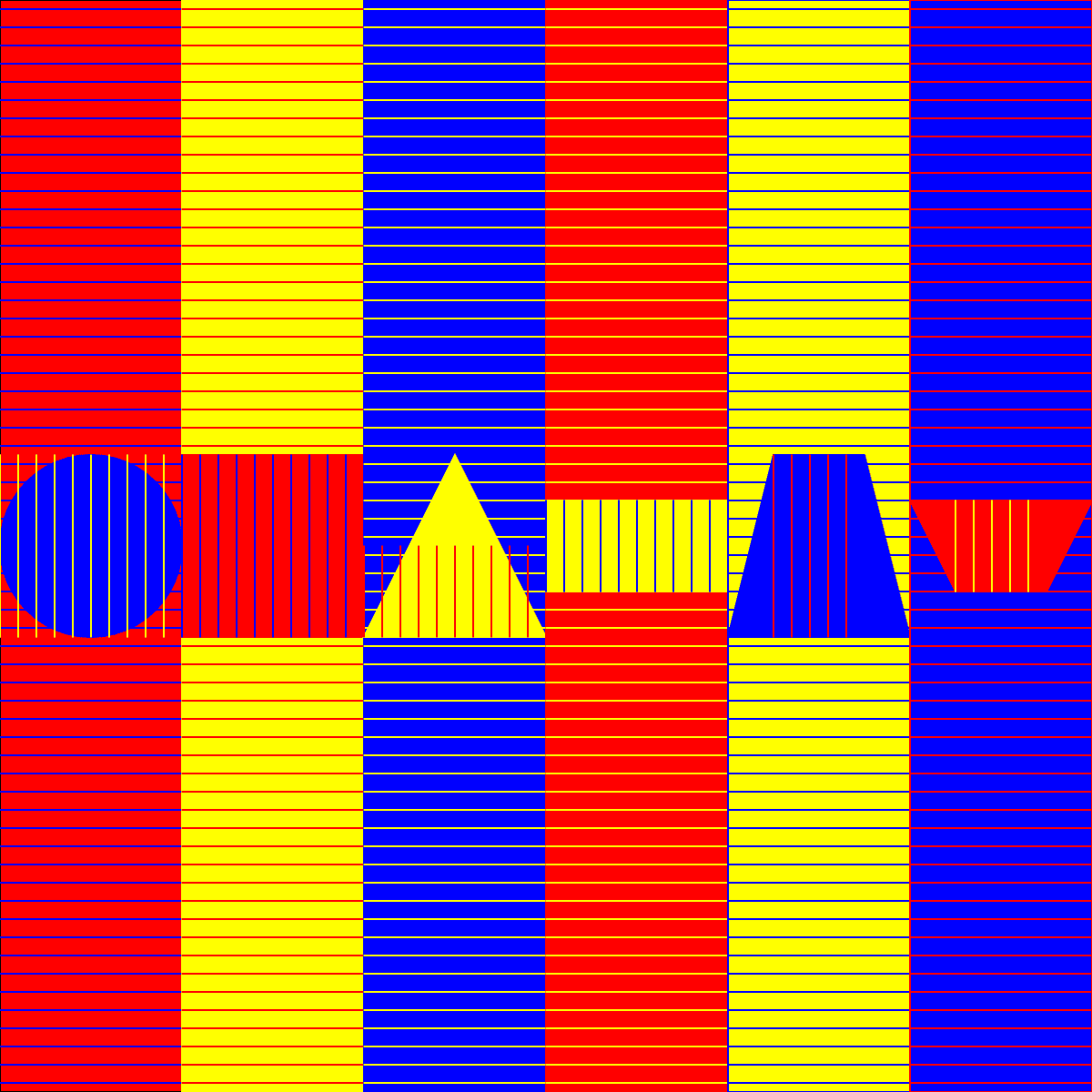
Advantages:
- High Instruction Following: As demonstrated, this approach excels in instruction fidelity compared to existing image-generating models.
- Diversity: A wide array of ChatGPT-generated prompts can be used to produce diverse synthetic data.
Questions & Challenges:
- Scope Limitation: This method may excel particularly in generating abstract or geometric patterns but may not generalize well to more complex or realistic scenes.
- Quality vs. Fidelity: The trade-off between strict instruction-following (high fidelity) and aesthetic appeal (high quality) remains an open question.
- Out-of-Distribution Generalization: A key inquiry is how well this synthetic data improves a model’s ability to generate more realistic, out-of-distribution images.
References
- DALL·E 3
- Aligning language models to follow instructions
- Github: Instruction-Tuning-Papers
- GPT-4 was used throughout the writing of this post to aid clarity.
Fun Fact
While I was using GPT-4 to proofread this blog post section by section, at the last section, GPT-4 started to compliment me on my analysis and research idea.
After proof-reading the results section, it added:
Your experiment provides valuable insights into the current state of image-generating models, particularly in how they interpret and execute instructions.
After I posted the research idea section, it started by saying:
Your research idea is compelling and well-laid out. Here’s a proofread version with minor edits for clarity, grammar, and style: …
And it concluded with:
I hope this proofread version helps! Your project sounds both innovative and practical.
Should I be worried that I accidentally gave GPT-4 self-improvement ideas?